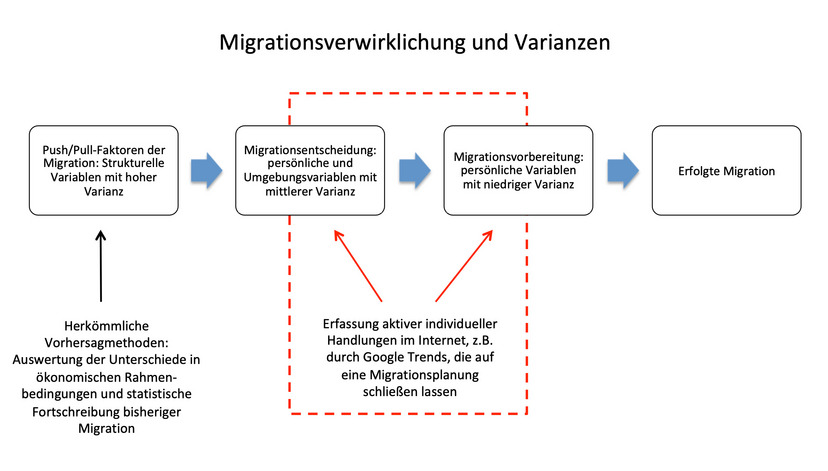
Bisherige Migrationsvorhersagen basieren entweder auf einer rein mathematischen Fortschreibung bisheriger Migration oder auf der Einschätzung von sozio-ökonomischen Rahmenbedingungen, ohne ihre jeweilige Stärke oder den Wirkungszeitpunkt explizit zu kennen. Dadurch erhöht sich die Ungenauigkeit möglicher Vorhersagen enorm. Im Gegensatz dazu stellt die in den letzten Jahren fortgeschrittene Erfassung der Internetnutzung und das Vorhandensein dieser Big Data eine neue Möglichkeit dar, um daraus eine realistische Trendvorhersage abzuleiten.
Das Projekt „Migration Forecast EU“ hat einen Beitrag für die Migrationsforschung geleistet, indem es explorativ die Möglichkeiten der Vorhersage von EU-Binnenmigration nach Deutschland anhand von digitalen Daten ausgelotet hat: Im Projekt wurde ermittelt, ob eine bessere Migrationsvorhersage auf Basis von digitalen Daten im Vergleich zu den herkömmlichen statistischen Methoden möglich ist.
Hierbei bildeten Google-Suchanfragen, die auf eine Migrationsplanung von Personen aus den EU-Staaten nach Deutschland schließen lassen, die hauptsächliche Datengrundlage. Wir haben eine Data Story zusammengestellt, die die Projektidee darlegt:
Deutsch: https://public.flourish.studio/story/1154407/
Englisch: https://public.flourish.studio/story/1154375/
Nach Abschluss der Modellierungsphase wurde deutlich, dass sich die Migrationsvorhersage zwar durch Google-Trends-Daten verbessern lassen, jedoch nur in einem sehr geringen Maße. Die Gründe hierfür liegen in der mangelnden Datenqualität bzw. technischen Limitationen von Google-Trends-Daten (die sich in Zukunft verbessern könnten) und der individuellen Migrationsvorbereitung und -planung, die weiterhin zu einem beträchtlichen Teil „offline“ und über andere Kommunikationskanäle vollzogen werden. Die ursprüngliche Idee, ein eigenes automatisiertes Vorhersageinstrument zu entwicklen, war auf Basis dieser Ergebnisse nicht mehr gerechtfertigt.