Prognosen gehen davon aus, dass das Volumen digital verfügbarer Daten zwischen 2018 und 2025 von 33 Zettabyte auf 175 Zettabyte – also auf 530 Prozent der ursprünglichen Menge – steigen wird. Überträgt man diese Berechnung auf eine hypothetische Gewichtszunahme einer 80 Kilo schweren Person, wäre sie sieben Jahre später etwa 424 Kilo schwer. Der Vergleich versinnbildlicht die schier unvorstellbare Größenordnung heutiger und zukünftiger Datenmengen. Parallel dazu wird erwartet, dass der potenziell Wert dieses „Datenschatzes“ in Europa circa 829 Milliarden Euro im Jahr 2025 betragen wird. Diese und andere Prognosen über die Menge und den Wert von Daten zeigen, dass uns das Thema in den kommenden Jahren immer stärker begleiten wird, der Fokus der Diskussion aktuell jedoch häufig auf wirtschaftlichen Fragen liegt. Welche sozialen und gesellschaftlichen Potenziale sich durch den Zugang zu Daten ergeben, bleibt dabei oftmals ungeklärt.
Europas Datenaltruismus – wie sieht der Weg dorthin aus?
Die jüngste Antwort auf datenpolitische Fragen entstammt mit dem Data Governance Act den Federn der Europäischen Kommission. Mit diesem hat sich Brüssel das ambitionierte Ziel gesetzt, Bürger:innen zum Teilen auch sensibler Daten für gesellschaftliche Zwecke zu animieren. Die aktuellen Beispiele zur Behandlung der pandemischen Lage zeigen nicht zuletzt auf, dass das grundsätzlich keine schlechte Idee ist. Doch einige Fragen müssen für den „vertrauensvollen Datenaltruismus“ noch geklärt werden, damit dieser im Einklang bestehender Grundrechte ausgeübt werden kann. Dafür werden auf europäischer, nationaler oder kommunaler Ebene bereits Modelle diskutiert, die das Teilen von Daten ermöglichen sollen. Immer häufiger sind deshalb Ansätze wie Datentreuhänder, Data Spaces, Data Commons im Gespräch.
Im Dschungel der Datenteilungsmodelle
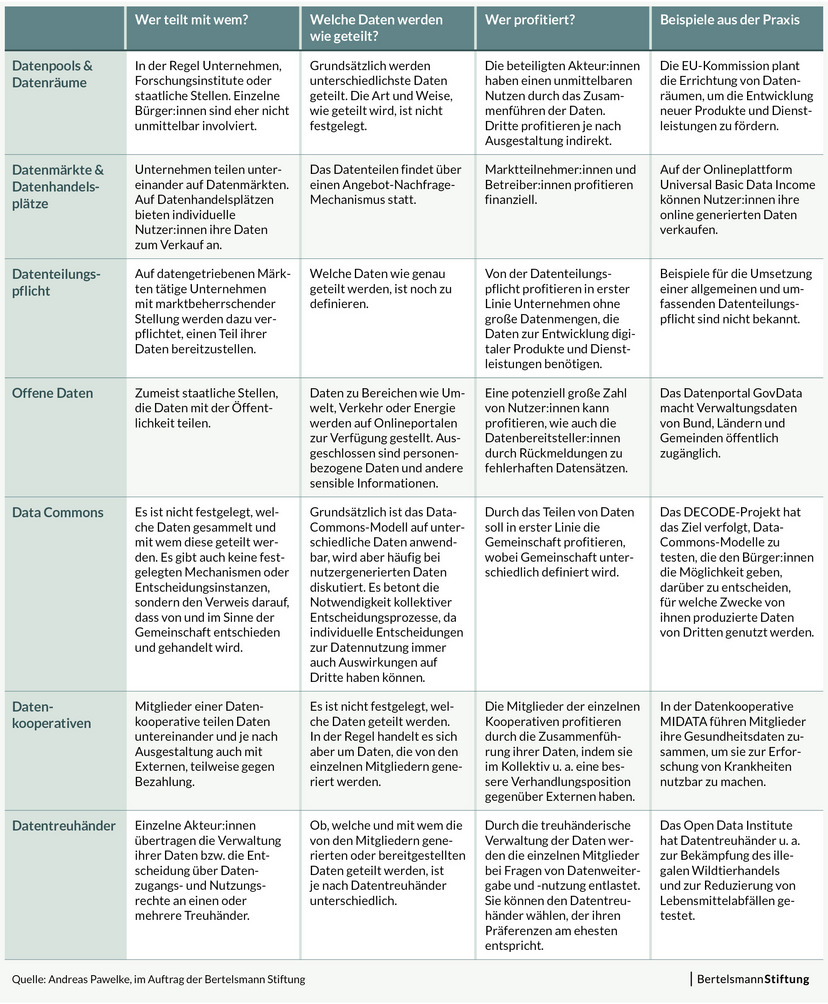
Die Debatte zum Königsweg des Datenteilens verdeutlicht, dass oftmals ein Verständnis dafür fehlt, was hinter den Begriffen steckt und wie die Ansätze sich voneinander unterscheiden. Auffällig ist außerdem, dass es zurzeit an einer kompakten Übersicht bestehender Modelle und konkreter Praxisbeispiele mangelt. Andreas Pawelke hat deshalb ein Panorama der Datenteilungsmodelle erarbeitet und nach folgenden Fragen strukturiert:
- Wer stellt Daten wem zur Verfügung?
- Welche Daten werden dabei berücksichtigt?
- Wer profitiert von diesem Austausch?
- Gibt es bereits Beispiele aus der Praxis?
Die Auflistung ergibt dabei ein heterogenes Bild der Funktions- und Wirkungsweisen von Datenteilungsmodellen. Die Übersicht kann helfen, den konkreten Nutzen für Einzelne und Gesellschaft zu evaluieren. Dabei sollte der Blick nicht alleine auf die technische Umsetzbarkeit, sondern auch auf die kontextuelle Einbettung gerichtet werden.