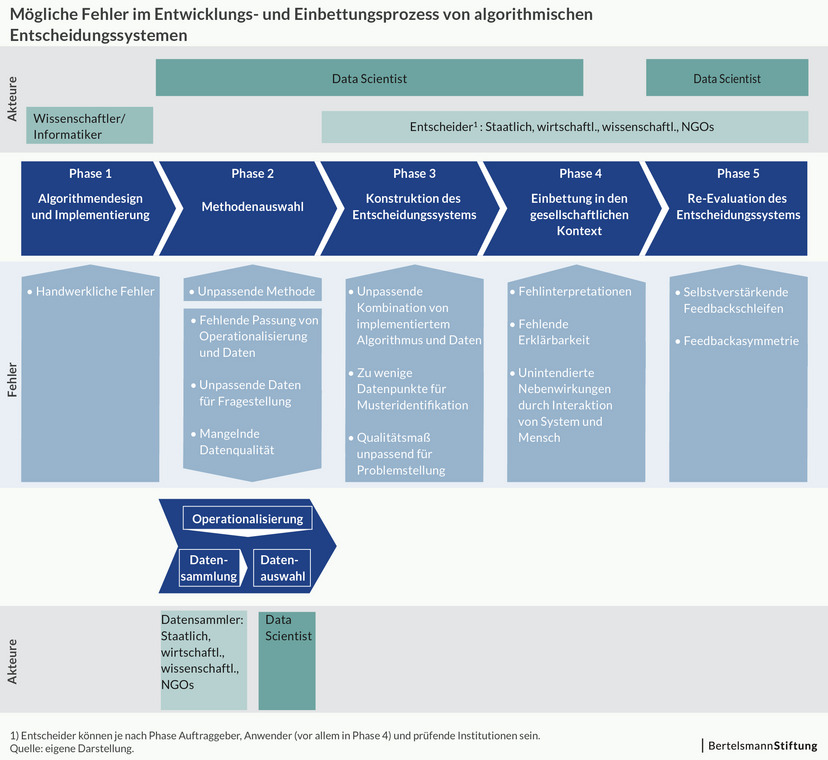
Wo algorithmische Systeme gebaut werden, sind viele Menschen involviert und ver-antwortlich: Wissenschaftler, Programmierer, Data Scientists sowie staatliche und wirtschaftliche Institutionen oder NGOs als Datensammler, Anwender oder Überprü-fer. Sie alle treffen Entscheidungen im Prozess, den ein algorithmisches System von seiner Entwicklung bis zur Evaluation durchläuft. Diesen Prozess beschreibt das Ar-beitspapier „Wo Maschinen irren können“ (Link zum Papier einfügen). Es ordnet Ver-antwortlichkeiten zu, um einer Diffusion der Verantwortung in komplexen Systemen („Mathwashing“) entgegenzuwirken.
In den fünf Prozess-Phasen kann vieles schiefgehen. Fehler kön-nen in allen fünf auftreten - mit unterschiedlich weitreichenden Auswirkungen. In der ersten Phase des Algorithmendesigns werden Fehler meist schnell entdeckt und sind daher selten. Besonders häufig tauchen Fehler in der vierten Phase auf, der Einbettung in die gesellschaftliche Praxis. Hier interagieren Anwender mit dem algorithmischen System und können das Ergebnis einer Prognose zum Beispiel falsch interpretieren. Das kann folgenschwer sein, etwa wenn es um die Rückfälligkeitsprognose von Straf-tätern geht. Auch in der fünften Phase, der Re-Evaluation des Entscheidungssystems, können Fehler etwa Diskriminierungen zur Folge haben. Das kann beispielsweise pas-sieren, wenn das System Feedback erhält, das sich selbst verstärkt. Ein Beispiel: Beim Predicitive Policing fährt die Polizei auf Grundlage der Systemprognosen vermehrt Streife in einem Viertel, dadurch entdeckt sie dort auch mehr Kleinkriminalität und es kommt zu mehr Festnahmen. Das System lernt daraus, dass es dort mehr Kriminalität gibt und empfiehlt dort noch mehr Kontrollen.